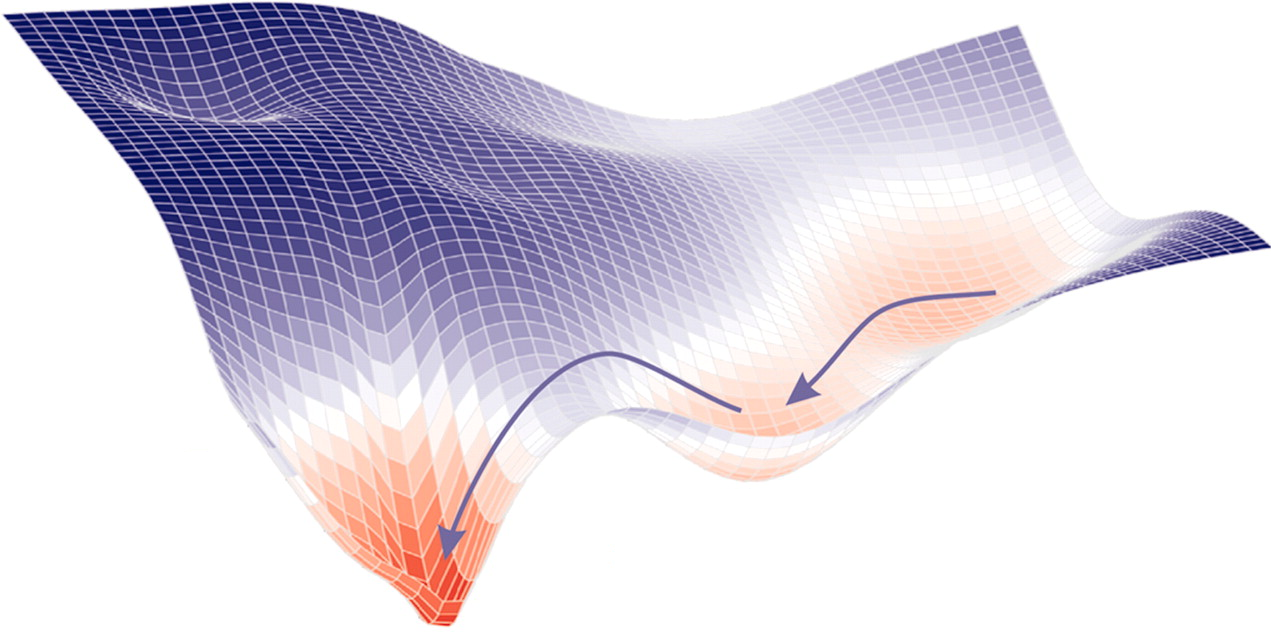
Why Does Batch Normalization Work?
Batch Normalization is often explained as a method for reducing “Internal Covariate Shift,” but growing evidence points instead to its ability to smooth the optimization landscape and make training more robust. Through interactive demos and reproducible experiments, this overview shows how Batch Normalization enhances convergence, remains effective even under artificially introduced covariate shifts, and reduces dependence on initialization—ultimately speeding up and stabilizing neural network training.